SAP Datasphere + ChatGPT: Construyendo una Capa de Análisis de Autoservicio

El Problema que Nadie Menciona en SAP Analytics
SAP lleva más de una década prometiendo análisis de autoservicio. Desde las queries de BW hasta Lumira y Analytics Cloud, cada generación de herramientas ha hecho la misma promesa: los usuarios de negocio podrán responder sus propias preguntas sin esperar a IT. Y cada generación ha fallado por la misma razón: las herramientas siguen exigiendo que los usuarios entiendan el modelo de datos.
Que los ingresos de ventas estén en la tabla de hechos ACDOCA con un filtro de fecha de contabilización en BUDAT, código de empresa en RBUKRS y centro de beneficio en PRCTR no es algo que debería saber un director regional de ventas. Ellos quieren preguntar "¿cuáles fueron nuestros 10 mejores clientes por facturación en el primer trimestre de 2026 para la región EMEA?" y obtener una respuesta. No un tutorial sobre cómo construir una query.
SAP Datasphere (el antiguo Data Warehouse Cloud rebautizado) ha mejorado notablemente el problema de la capa de datos. La federación, la replicación y la capa semántica de negocio ofrecen una vista unificada de datos SAP y no SAP. Pero el último tramo —permitir que usuarios no técnicos consulten esos datos de forma natural— sigue sin estar en el producto estándar.
Eso es lo que vamos a resolver. Construiremos una interfaz en lenguaje natural sobre SAP Datasphere que utiliza GPT-4 de OpenAI (a través del Generative AI Hub de SAP AI Core, o directamente) para traducir preguntas en inglés llano a consultas SQL, ejecutarlas contra Datasphere y devolver resultados formateados. El sistema completo tardó tres semanas en construirse y lleva en producción desde noviembre de 2025.
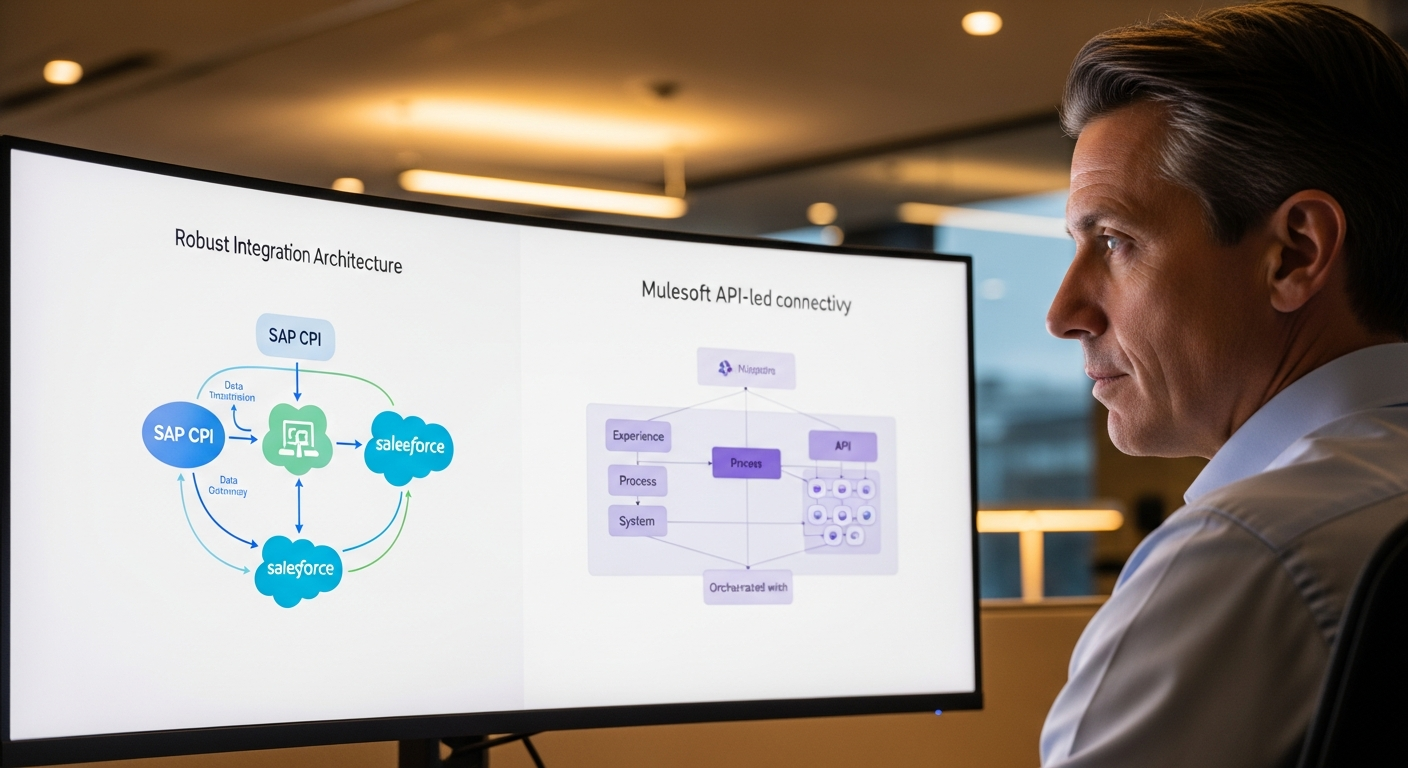
Visión General de la Arquitectura
Esto es lo que vamos a construir:
- SAP Datasphere — la plataforma de datos, con datos replicados y federados desde S/4HANA, BW/4HANA y fuentes externas
- Un servicio middleware en Python — gestiona la conversación, la consulta de metadatos y la generación de queries
- OpenAI GPT-4 (o GPT-4o) — traduce lenguaje natural a SQL
- Un frontend web sencillo — interfaz estilo chat donde los usuarios escriben sus preguntas
- SAP Analytics Cloud (opcional) — para usuarios que quieran visualizar los resultados como gráficos
El truco que hace que esto funcione de verdad (a diferencia de las decenas de demos de "habla con tu base de datos" que se desmoronan con datos reales) es la capa de metadatos semánticos. No le pasamos el esquema de tablas en bruto a GPT-4 y esperamos lo mejor. Construimos un catálogo de metadatos curado que describe cada tabla y columna en lenguaje de negocio, incluye ejemplos de valores válidos, especifica relaciones de join y proporciona plantillas de query para preguntas frecuentes.
Configurar SAP Datasphere para Acceso por API
Primero, asegurémonos de que tu tenant de Datasphere es accesible vía API. Necesitarás:
- Un tenant de SAP Datasphere con la capacidad "Consumption API" habilitada
- Un usuario de base de datos con acceso de lectura a tus modelos analíticos
- Los datos de conexión ODBC/JDBC desde la configuración de Database Access de Datasphere
En Datasphere, ve a Space Management > tu espacio > Database Access. Crea un usuario de base de datos si aún no tienes uno. Anota el host, el puerto y el nombre de esquema — los necesitarás para conectarte desde Python.
# Datos de conexión desde Datasphere Database Access
DSP_HOST = "your-tenant.hana.prod-eu10.hanacloud.ondemand.com"
DSP_PORT = 443
DSP_USER = "your_db_user"
DSP_PASSWORD = "your_password" # Usa variables de entorno en producción
DSP_SCHEMA = "your_space_schema"Para la conectividad con Python, usamos la librería hdbcli (el cliente SAP HANA para Python):
from hdbcli import dbapi
def get_datasphere_connection():
conn = dbapi.connect(
address=DSP_HOST,
port=DSP_PORT,
user=DSP_USER,
password=DSP_PASSWORD,
encrypt=True,
sslValidateCertificate=True
)
return conn
def execute_query(query, params=None):
conn = get_datasphere_connection()
cursor = conn.cursor()
try:
cursor.execute(query, params or [])
columns = [desc[0] for desc in cursor.description]
rows = cursor.fetchall()
return columns, rows
finally:
cursor.close()
conn.close()Construyendo la Capa de Metadatos Semánticos
Esta es la parte más importante de todo el sistema. Sin buenos metadatos, GPT-4 generará SQL sintácticamente correcto que devuelve resultados incorrectos. Y los resultados incorrectos que parecen correctos son mucho peores que un mensaje de error.
Crea un archivo de catálogo de metadatos (yo uso YAML, pero JSON también funciona):
# metadata/sales_analytics.yaml
tables:
- name: V_SALES_ORDERS
description: "Datos de pedidos de venta incluyendo cabecera y posiciones, replicados desde tablas VBAK/VBAP de S/4HANA"
business_context: "Contiene todos los pedidos de venta. Úsalo para análisis de ingresos, seguimiento de volumen de pedidos y patrones de compra de clientes."
columns:
- name: VBELN
description: "Número de pedido de venta"
business_name: "Número de Pedido"
data_type: "NVARCHAR(10)"
example_values: ["0000012345", "0000067890"]
- name: ERDAT
description: "Fecha en que se creó el pedido"
business_name: "Fecha del Pedido"
data_type: "DATE"
notes: "Formato YYYY-MM-DD. Para análisis trimestrales, usa QUARTER(ERDAT)"
- name: KUNNR
description: "Número de cliente, clave foránea de V_CUSTOMERS"
business_name: "Cliente"
data_type: "NVARCHAR(10)"
join_to: "V_CUSTOMERS.KUNNR"
- name: NETWR
description: "Valor neto del pedido en moneda del documento"
business_name: "Valor del Pedido"
data_type: "DECIMAL(15,2)"
aggregation: "SUM para totales, AVG para valor medio de pedido"
notes: "Combinar siempre con WAERK (moneda) al mostrar. Para informes consolidados, usa NETWR_LC (moneda local) o NETWR_GC (moneda de grupo)"
- name: WAERK
description: "Código de moneda del documento"
business_name: "Moneda"
data_type: "NVARCHAR(5)"
example_values: ["EUR", "USD", "GBP"]
- name: VKORG
description: "Organización de ventas"
business_name: "Org. de Ventas"
data_type: "NVARCHAR(4)"
valid_values:
"1000": "EMEA"
"2000": "Américas"
"3000": "APAC"
- name: AUART
description: "Tipo de documento de ventas"
business_name: "Tipo de Pedido"
data_type: "NVARCHAR(4)"
valid_values:
"TA": "Pedido Estándar"
"KE": "Reposición de Consignación"
"RE": "Devoluciones"
- name: NETWR_GC
description: "Valor neto del pedido en moneda de grupo (EUR)"
business_name: "Valor del Pedido (EUR)"
data_type: "DECIMAL(15,2)"
aggregation: "SUM para totales. Usar para comparaciones entre regiones"
- name: V_CUSTOMERS
description: "Datos maestros de clientes de KNA1/KNB1"
business_context: "Detalles del cliente incluyendo nombre, región, sector e información de crédito"
columns:
- name: KUNNR
description: "Número de cliente"
business_name: "Número de Cliente"
data_type: "NVARCHAR(10)"
- name: NAME1
description: "Nombre del cliente"
business_name: "Nombre del Cliente"
data_type: "NVARCHAR(35)"
- name: LAND1
description: "Código de país"
business_name: "País"
data_type: "NVARCHAR(3)"
- name: BRSCH
description: "Código de sector industrial"
business_name: "Sector"
data_type: "NVARCHAR(4)"
valid_values:
"0001": "Fabricación"
"0002": "Comercio Minorista"
"0003": "Servicios"
"0004": "Tecnología"
common_queries:
- question: "top customers by revenue"
template: |
SELECT c.NAME1 as customer_name, SUM(s.NETWR_GC) as total_revenue
FROM V_SALES_ORDERS s JOIN V_CUSTOMERS c ON s.KUNNR = c.KUNNR
WHERE s.ERDAT BETWEEN '{start_date}' AND '{end_date}'
AND s.AUART = 'TA'
GROUP BY c.NAME1 ORDER BY total_revenue DESC LIMIT {limit}
- question: "revenue by region"
template: |
SELECT s.VKORG as sales_org, SUM(s.NETWR_GC) as revenue
FROM V_SALES_ORDERS s
WHERE s.ERDAT BETWEEN '{start_date}' AND '{end_date}'
AND s.AUART NOT IN ('RE')
GROUP BY s.VKORG ORDER BY revenue DESCObserva cuánto contexto estamos proporcionando. Cada columna tiene un nombre de negocio, valores de ejemplo, mapeos de valores válidos y notas sobre cómo usarla correctamente. La sección common_queries da a GPT-4 plantillas para preguntas frecuentes, reduciendo la posibilidad de errores.
El Motor de Generación de Queries
Este es el núcleo del sistema: el módulo que toma una pregunta en lenguaje natural, la combina con los metadatos y le pide a GPT-4 que genere SQL:
import openai
import yaml
import json
class QueryGenerator:
def __init__(self, metadata_path, openai_api_key):
with open(metadata_path) as f:
self.metadata = yaml.safe_load(f)
self.client = openai.OpenAI(api_key=openai_api_key)
self.conversation_history = []
def _build_system_prompt(self):
schema_description = []
for table in self.metadata['tables']:
cols = []
for col in table['columns']:
col_desc = f" - {col['name']} ({col['business_name']}): {col['description']}"
if 'valid_values' in col:
col_desc += f" Valid values: {json.dumps(col['valid_values'])}"
if 'notes' in col:
col_desc += f" Note: {col['notes']}"
cols.append(col_desc)
schema_description.append(
f"Table: {table['name']}\n"
f"Description: {table['description']}\n"
f"Business context: {table['business_context']}\n"
f"Columns:\n" + "\n".join(cols)
)
common_q = ""
if 'common_queries' in self.metadata:
for q in self.metadata['common_queries']:
common_q += f"\nExample - '{q['question']}':\n{q['template']}\n"
return f"""You are a SQL query generator for SAP Datasphere (HANA SQL syntax).
You translate natural language questions into SQL queries.
IMPORTANT RULES:
1. Only use tables and columns from the schema below. Never invent columns.
2. Use HANA SQL syntax (TOP is not supported, use LIMIT instead).
3. When comparing dates, use TO_DATE('YYYY-MM-DD') format.
4. Always exclude returns (AUART = 'RE') from revenue calculations unless asked.
5. Use NETWR_GC (group currency EUR) for cross-region comparisons.
6. When asked about "Q1", "Q2" etc., map to: Q1=Jan-Mar, Q2=Apr-Jun, Q3=Jul-Sep, Q4=Oct-Dec.
7. Return ONLY the SQL query, no explanation.
8. If the question cannot be answered with available tables, say "CANNOT_ANSWER:" followed by explanation.
SCHEMA:
{chr(10).join(schema_description)}
EXAMPLE QUERIES:
{common_q}"""
def generate_query(self, user_question):
if not self.conversation_history:
self.conversation_history.append({
"role": "system",
"content": self._build_system_prompt()
})
self.conversation_history.append({
"role": "user",
"content": user_question
})
response = self.client.chat.completions.create(
model="gpt-4",
messages=self.conversation_history,
temperature=0.1,
max_tokens=500
)
sql = response.choices[0].message.content.strip()
self.conversation_history.append({
"role": "assistant",
"content": sql
})
return sqlValidación y Seguridad de Queries
No puedes ejecutar SQL generado por IA sin validación. GPT-4 es bueno, pero ocasionalmente genera queries que escanearían tablas enteras, producirían productos cartesianos o, en casos adversariales, intentarían modificar datos.
import sqlparse
class QueryValidator:
BLOCKED_KEYWORDS = ['INSERT', 'UPDATE', 'DELETE', 'DROP', 'ALTER',
'CREATE', 'TRUNCATE', 'MERGE', 'GRANT', 'REVOKE']
MAX_RESULT_ROWS = 10000
def __init__(self, allowed_tables):
self.allowed_tables = {t.upper() for t in allowed_tables}
def validate(self, sql):
errors = []
# Verificar intentos de modificación de datos
parsed = sqlparse.parse(sql)
for statement in parsed:
stmt_type = statement.get_type()
if stmt_type and stmt_type.upper() != 'SELECT':
errors.append(f"Solo se permiten sentencias SELECT, se recibió {stmt_type}")
# Verificar palabras clave bloqueadas
sql_upper = sql.upper()
for keyword in self.BLOCKED_KEYWORDS:
if keyword in sql_upper.split():
errors.append(f"Palabra clave bloqueada: {keyword}")
# Extraer nombres de tablas y validar
tables_used = self._extract_tables(sql)
unauthorized = tables_used - self.allowed_tables
if unauthorized:
errors.append(f"Tablas no autorizadas: {unauthorized}")
# Asegurar que existe cláusula LIMIT
if 'LIMIT' not in sql_upper:
sql = sql.rstrip(';') + f' LIMIT {self.MAX_RESULT_ROWS}'
return errors, sql
def _extract_tables(self, sql):
tables = set()
tokens = sql.upper().split()
for i, token in enumerate(tokens):
if token in ('FROM', 'JOIN'):
if i + 1 < len(tokens):
table_name = tokens[i + 1].strip('(),')
if table_name and not table_name.startswith('('):
tables.add(table_name)
return tablesEl validador comprueba tres cosas: que no haya sentencias de modificación de datos, que solo se usen tablas de la lista blanca y que exista un límite obligatorio de filas. El usuario de base de datos que creamos en Datasphere también tiene acceso de solo lectura, de modo que aunque una query maliciosa supere la validación, la propia base de datos no permitirá modificaciones.
Construyendo la Capa Conversacional
Un sistema de query única es útil, pero el análisis de autoservicio real requiere contexto conversacional. Los usuarios quieren hacer una pregunta, ver los resultados y luego hacer una pregunta de seguimiento: "ahora desglósalo por trimestre" o "excluye el sector público".
class AnalyticsAssistant:
def __init__(self, metadata_path, openai_key, datasphere_config):
self.generator = QueryGenerator(metadata_path, openai_key)
self.validator = QueryValidator(
allowed_tables=[t['name'] for t in self.generator.metadata['tables']]
)
self.dsp_config = datasphere_config
self.query_history = []
def ask(self, question):
# Generar SQL desde lenguaje natural
sql = self.generator.generate_query(question)
# Comprobar si el modelo indicó que no puede responder
if sql.startswith('CANNOT_ANSWER:'):
return {
'status': 'cannot_answer',
'message': sql.replace('CANNOT_ANSWER:', '').strip(),
'sql': None,
'data': None
}
# Validar el SQL generado
errors, validated_sql = self.validator.validate(sql)
if errors:
return {
'status': 'validation_error',
'message': f"Validación de query fallida: {'; '.join(errors)}",
'sql': sql,
'data': None
}
# Ejecutar contra Datasphere
try:
columns, rows = execute_query(validated_sql)
self.query_history.append({
'question': question,
'sql': validated_sql,
'row_count': len(rows)
})
return {
'status': 'success',
'sql': validated_sql,
'columns': columns,
'data': rows,
'row_count': len(rows)
}
except Exception as e:
# Si la query falla, pedir a GPT-4 que la corrija
fix_response = self.generator.generate_query(
f"La query anterior falló con el error: {str(e)}. "
f"Corrige la consulta SQL para responder a la pregunta original."
)
errors2, fixed_sql = self.validator.validate(fix_response)
if not errors2:
try:
columns, rows = execute_query(fixed_sql)
return {
'status': 'success',
'sql': fixed_sql,
'columns': columns,
'data': rows,
'row_count': len(rows),
'note': 'La query fue corregida automáticamente tras el fallo inicial'
}
except Exception as e2:
pass
return {
'status': 'error',
'message': f"Ejecución de query fallida: {str(e)}",
'sql': validated_sql,
'data': None
}Observa el bucle de autocorrección. Cuando una query generada falla (normalmente por un nombre de columna incorrecto o un problema de sintaxis), el sistema envía el error de vuelta a GPT-4 y le pide que corrija la query. En mi experiencia, esta autocorrección tiene éxito aproximadamente el 60% de las veces, lo que significa que los usuarios ven errores con menos frecuencia.
La Interfaz Web
El frontend es una aplicación Flask sencilla con una interfaz estilo chat. Sin lujos — el valor está en el backend, no en la UI:
from flask import Flask, render_template, request, jsonify, session
import uuid
app = Flask(__name__)
app.secret_key = 'your-secret-key'
assistants = {} # session_id -> AnalyticsAssistant
@app.route('/ask', methods=['POST'])
def ask():
session_id = session.get('id')
if not session_id:
session_id = str(uuid.uuid4())
session['id'] = session_id
if session_id not in assistants:
assistants[session_id] = AnalyticsAssistant(
metadata_path='metadata/sales_analytics.yaml',
openai_key=OPENAI_API_KEY,
datasphere_config=DSP_CONFIG
)
question = request.json.get('question', '')
result = assistants[session_id].ask(question)
# Formatear la respuesta
if result['status'] == 'success':
html_table = format_as_html_table(result['columns'], result['data'])
return jsonify({
'answer': html_table,
'sql': result['sql'],
'row_count': result['row_count'],
'status': 'success'
})
else:
return jsonify({
'answer': result['message'],
'sql': result.get('sql'),
'status': result['status']
})Precisión y Rendimiento en el Mundo Real
Tras ejecutar este sistema con 34 usuarios activos de los departamentos de ventas, finanzas y supply chain durante cinco meses, estos son los números reales:
| Métrica | Valor |
|---|---|
| Total de preguntas realizadas | 4.847 |
| Queries exitosas (resultados correctos) | 3.974 (82%) |
| Queries autocorregidas | 387 (8%) |
| Queries fallidas (usuario notificado) | 486 (10%) |
| Tiempo medio de respuesta | 3,2 segundos |
| Preguntas por usuario por semana | 7,1 |
| Tickets IT anteriores para informes ad hoc (mensual) | 45 |
| Tickets IT actuales para informes ad hoc (mensual) | 8 |
La tasa de precisión del 82% puede parecer baja, pero el contexto importa. Antes de este sistema, esos 34 usuarios tenían que construir sus propias historias en SAC (lo que la mayoría no podía hacer) o enviar tickets a IT y esperar entre 3 y 5 días hábiles. El 10% de fallos proviene principalmente de preguntas sobre datos que aún no están disponibles en Datasphere (datos de RRHH, por ejemplo) o preguntas genuinamente ambiguas ("¿cómo vamos?" no es una query que ningún sistema pueda responder).
Los Tipos de Preguntas que Mejor Funcionan
- Queries de agregación: "¿Cuáles son los ingresos totales por organización de ventas en el primer trimestre de 2026?" — 95% de precisión
- Queries de ranking: "Los 20 mejores clientes por número de pedidos este año" — 93% de precisión
- Queries de comparación: "Comparar ingresos T1 2025 vs T1 2026 por región" — 88% de precisión
- Queries de filtrado: "Mostrar todos los pedidos superiores a 100.000 € de clientes alemanes" — 91% de precisión
- Queries de tendencia: "Tendencia de ingresos mensual de los últimos 12 meses" — 85% de precisión
- Joins complejos: "Ingresos por sector industrial del cliente para la región APAC" — 78% de precisión
Los Que Fallan Más
- Cálculos con varios pasos: "Tasa de crecimiento interanual por categoría de producto" — 62% de precisión (requiere queries anidadas)
- Preguntas con referencias temporales ambiguas: "Pedidos recientes" — 55% de precisión (¿cuánto es reciente?)
- Preguntas que requieren conocimiento de negocio no incluido en los metadatos: "¿Qué clientes están en riesgo de abandono?" — 40% de precisión (el modelo no conoce tu definición de churn)
Mejorar la Precisión con el Tiempo
La capa de metadatos es la palanca principal para mejorar la precisión. Cada vez que una query falla o devuelve resultados incorrectos, analizo el fallo y añado información a los metadatos:
- Añadir más queries de ejemplo. Cuando los usuarios hacen sistemáticamente preguntas con un patrón con el que el sistema tiene dificultades, añado una plantilla a la sección common_queries. Esto mejoró la precisión de la comparación interanual del 62% al 84%.
- Ampliar los mapeos de valores válidos. Los usuarios dicen "Alemania" pero la base de datos almacena "DE". Añadir mapeos de nombre de país a código en los metadatos permite que GPT-4 haga la traducción automáticamente.
- Añadir anotaciones de reglas de negocio. Los "ingresos" siempre deben excluir devoluciones (AUART = 'RE') y transferencias internas (AUART = 'ZIV'). Documentar esto en los metadatos hace que GPT-4 aplique estos filtros automáticamente.
- Crear definiciones de vista para patrones complejos. Cuando una pregunta requiere una query multi-join compleja con la que GPT-4 tiene problemas, crea una vista en Datasphere que pre-une las tablas y añade esa vista a los metadatos como una tabla única y sencilla.
Análisis de Costes
Hablemos de lo que cuesta ejecutar este sistema:
- Costes de la API de OpenAI: Media de 4.800 queries/mes x ~2.000 tokens por query x $0,03/1K tokens (GPT-4) = ~$288/mes. Cambiar a GPT-4o reduce esto a ~$48/mes con una precisión comparable para la generación de SQL.
- SAP Datasphere: Ya pagado como parte de la licencia SAP de la organización. El coste incremental del usuario de API es mínimo.
- Infraestructura: Una VM pequeña para el middleware Python (~$50/mes) y hosting para el frontend web (~$20/mes).
- Coste mensual total: ~$120/mes con GPT-4o, ~$360/mes con GPT-4.
Compara esto con el coste de 45 tickets IT al mes para informes ad hoc. A una tarifa interna de IT de $120/ticket (incluyendo tiempo del analista, tiempo en cola y revisión), eso supone $5.400/mes en personal IT. El sistema ahorra más de $5.000/mes mientras da respuestas instantáneas a los usuarios en lugar de una espera de 3 a 5 días.
Consideraciones de Seguridad
Conectar un sistema de IA a tus datos SAP plantea preocupaciones legítimas de seguridad. Así es como las gestionamos:
- Los datos no van a OpenAI. Solo la pregunta y el esquema de metadatos se envían a la API. Los resultados reales de las queries se mantienen dentro de tu red. GPT-4 genera SQL; nunca ve los datos.
- Seguridad a nivel de fila. Las vistas de Datasphere utilizan privilegios analíticos para restringir los datos según el perfil de autorización del usuario conectado. Un director de ventas de EMEA solo ve datos de EMEA, aunque el SQL generado no filtre por región.
- Registro de auditoría de queries. Cada pregunta, SQL generado y tamaño del conjunto de resultados se registra con la identidad del usuario y la marca de tiempo. Esto crea un rastro de auditoría completo.
- Saneamiento de entradas. El validador de SQL previene ataques de inyección, y el usuario de base de datos tiene permisos de solo lectura. Incluso si alguien intenta ser ingenioso, el peor resultado posible es una query fallida.
Integración con SAP Analytics Cloud
Algunos usuarios prefieren resultados visuales a tablas. Para estos usuarios, añadimos una integración opcional con SAP Analytics Cloud (SAC). Cuando una query devuelve datos de series temporales o categóricos, el sistema puede generar automáticamente una historia en SAC a través de la API de SAC:
def push_to_sac(columns, data, chart_type='bar'):
# Crear un dataset en SAC
sac_client = SACClient(
tenant_url=SAC_TENANT_URL,
client_id=SAC_CLIENT_ID,
client_secret=SAC_CLIENT_SECRET
)
# Subir los resultados como un dataset de SAC
dataset_id = sac_client.create_dataset(
name=f"NL_Query_{datetime.now().strftime('%Y%m%d_%H%M%S')}",
columns=columns,
data=data
)
# Generar una historia simple con el gráfico
story_url = sac_client.create_story(
dataset_id=dataset_id,
chart_type=chart_type,
title="Resultado de Consulta Analítica"
)
return story_urlEsta es la parte más débil del sistema, honestamente. La API de SAC para la creación programática de historias es limitada, y los resultados parecen genéricos. La mayoría de los usuarios acaban prefiriendo las tablas HTML porque se cargan al instante, mientras que la integración con SAC añade 8-10 segundos de latencia. Pero para los usuarios que necesitan incrustar resultados en presentaciones, disponer de la opción SAC es valioso.
Lecciones de Cinco Meses en Producción
Los metadatos nunca están terminados. Dedico aproximadamente 2 horas por semana a mantener y ampliar el catálogo de metadatos. Se añaden nuevas tablas a Datasphere, las reglas de negocio cambian, los usuarios hacen preguntas sobre datos que antes no estaban mapeados. Este es trabajo operativo continuo, no una configuración única.
Los usuarios necesitan formación para hacer buenas preguntas. "Muéstrame todo" no es una query útil. Realizamos una sesión de formación de 30 minutos mostrando a los usuarios cómo hacer preguntas específicas y respondibles. La tasa de fallos bajó del 18% al 10% tras la formación.
GPT-4 es mejor con SQL de HANA de lo que esperarías. El modelo maneja correctamente funciones específicas de HANA como ADD_DAYS, DAYSBETWEEN, ISOWEEK y QUARTER sin necesidad de prompting especial. También gestiona bien las jerarquías y las funciones de ventana, aunque los cálculos LAG/LEAD a veces producen errores de sintaxis que la autocorrección detecta.
El caché de preguntas repetidas ahorra dinero y tiempo. Aproximadamente el 30% de las preguntas son variantes de la misma query (solo con rangos de fechas o filtros diferentes). Una capa de caché simple que reconoce similitud semántica redujo los costes de API en un 25% y el tiempo de respuesta en un 60% para las queries en caché.
No subestimes el valor político. Cuando un CFO puede escribir "ingresos vs presupuesto por centro de coste para el primer trimestre" y obtener una respuesta instantánea durante una reunión de directivos, la credibilidad del equipo de datos se dispara. Varios de nuestros usuarios mencionaron específicamente esta capacidad al defender el presupuesto del equipo de datos durante la planificación anual. El sistema se paga solo en credibilidad organizacional.
Próximos Pasos
Estamos trabajando en tres mejoras:
- Refinamiento de queries multi-turno con vista previa de datos. Mostrar las primeras 5 filas de resultados y preguntar "¿es esto lo que esperabas?" antes de devolver el conjunto de datos completo. Esto detecta pronto los problemas de columnas o filtros incorrectos.
- Generación automática de metadatos. Usar GPT-4 para leer las definiciones de tablas de Datasphere y generar el catálogo de metadatos inicial, que luego un humano revisa y corrige. Esto reduciría el tiempo de configuración para nuevas tablas de horas a minutos.
- Entrada de voz vía Microsoft Teams. Varios usuarios pidieron la posibilidad de hacer preguntas por voz en reuniones de Teams. Estamos prototipando un bot de Teams que acepta voz, transcribe vía Whisper, genera la query y devuelve resultados como una tarjeta de Teams.
El patrón central —lenguaje natural enriquecido con metadatos a SQL— es aplicable mucho más allá de SAP. Cualquier fuente de datos estructurada con buenos metadatos puede consultarse de esta manera. Pero SAP es donde el patrón aporta más valor porque los modelos de datos de SAP son notoriamente difíciles de navegar para usuarios no técnicos. Cuando eliminas esa barrera, la demanda de análisis no solo aumenta, sino que cambia fundamentalmente quién en la organización puede tomar decisiones basadas en datos.